1. 서론
인간이 눈을 뜨고 세상을 즉각적으로 인식하는 것처럼, 인공지능이 세상을 '보는' 핵심 기술을 '객체 탐지(Object Detection)'라고 부른다.
객체 탐지(Object Detection)란 무엇인가?
먼저 기본 개념부터 짚고 가겠습니다. Object Detection (객체 탐지)은 이미지 또는 비디오에서 특정 개체(예: 사람, 자동차, 사물)를 식별하고 그 위치를 찾아내는 컴퓨터 비전 작업입니다.
AI 모델이 이 작업을 수행한다는 것은 구체적으로 다음을 의미합니다.
한 이미지 내에서 여러 객체를 찾아내고, 각 객체의 윤곽을 그리는 경계 상자(bounding box)를 탐지합니다.
알고리즘은 이미지를 입력으로 받아, 이 경계 상자와 객체 클래스(이름)의 목록을 출력합니다.
각 경계 상자에 대해 "이것은 95% 확률로 '사람'이다"와 같이 예측된 클래스와 그 신뢰도(confidence)를 함께 반환합니다.
결국, 이 기술은 AI가 두 가지 핵심 질문에 동시에 답하는 것과 같습니다.
"이것은 무엇인가?" (객체 식별)
"어디에 위치해 있는가?" (정확한 위치 파악)
오랫동안 AI 분야는 이 두 가지 질문에 동시에, 그리고 '빠르게' 답하는 데 어려움을 겪었습니다. 기존의 인식 방법들은 여러 단계를 거쳐야 했기 때문에, 단일 알고리즘 실행만으로는 객체를 실시간으로 감지하기 어려웠습니다.
바로 이 '속도'와 '정확도'의 딜레마를 해결하며 등장한 것이 오늘 우리가 자세히 알아볼 YOLO입니다.
2. YOLO의 탄생: 왜 "You Only Look Once"인가?
YOLO가 왜 인공지능 비전 분야에서 '혁신'으로 불리는지 이해하기 위해서는 그 이전의 방식을 먼저 살펴볼 필요가 있다.
YOLO 이전: 2단계 탐지기 (2-Stage Detectors)
R-CNN 계열로 대표되는 초기 객체 탐지 모델들은 이미지를 '두 번' 봐야 했다.
후보 영역 탐색: 먼저 이미지 전체를 훑으며 '여기 뭔가 있을 것 같다'라고 판단되는 수천 개의 후보 영역(Region Proposal)을 찾는다.
분류: 그 수천 개의 영역들을 하나씩 다시 정밀하게 살펴보며 '이것은 사람이네', '저것은 고양이네'라고 분류한다.
이는 마치 돋보기를 들고 방 안 구석구석을 샅샅이 뒤지는 탐정의 방식과 같다. 정확도는 높을 수 있으나, 하나의 이미지를 처리하는 데 상당한 시간이 소요되었다.
YOLO의 혁신: 1단계 탐지기 (1-Stage Detectors)
YOLO(You Only Look Once)는 이름 그대로, 이 모든 과정을 '단 한 번에' 끝내는 혁신적인 접근법을 제시했다.
YOLO는 이미지 전체를 단 한 번(Look Once) 훑어보는 것만으로 '어디에(위치)' '무엇이(종류)' 있는지를 동시에 예측한다. 이는 마치 방문을 한 번 쓱 쳐다보고도 방 안의 모든 사람과 사물의 위치를 즉각 파악하는 인간의 시각 능력과 유사하다.
이 '실시간(Real-Time) 처리 속도'가 바로 YOLO가 자율주행, CCTV 보안, 그리고 로보틱스 연구에 필수적인 기술로 자리 잡은 이유이다. 1초에도 수십 번씩 변하는 현실 세계에 즉각 반응해야 하는 로봇에게, YOLO의 속도는 선택이 아닌 필수였다.
3. YOLO의 구조: 3단계 '공장 조립 라인'
YOLO 모델의 내부 구조는 크게 세 부분으로 나눌 수 있습니다. 거대한 '공장 조립 라인'을 상상해 보세요.
1. 백본 (Backbone): '눈' (특징 추출기)
역할: 이미지의 원본 데이터를 받아 핵심 특징(feature)을 추출합니다.
작동: 이미지가 이 '백본'이라 불리는 깊은 컨볼루션 신경망(CNN)을 통과합니다. 초기 레이어에서는 간단한 선이나 질감을, 깊은 레이어로 갈수록 더 복잡한 형태(바퀴, 눈, 코 등)를 인식합니다.
비유: 공장의 첫 단계. 원재료(이미지)에서 쓸만한 부품(특징)들을 모조리 뽑아내는 라인입니다.
2. 넥 (Neck): '신경망' (특징 융합기)
역할: 백본에서 추출된 다양한 크기의 특징들을 융합(combine)합니다.
작동: 백본은 이미지의 '큰 특징(예: 사람의 전신)'과 '작은 특징(예: 사람의 얼굴)'을 서로 다른 층에서 추출합니다. '넥'은 이 정보들을 위아래로 섞어주며, "큰 그림"과 "세부 사항"을 모두 고려한 풍부한 특징 맵을 만듭니다.
비유: 여러 부품 라인(백본)에서 온 크고 작은 부품들(특징)을 한데 모아 조립하기 좋게 정리하고 결합하는 중간 라인입니다.
3. 헤드 (Head): '뇌' (최종 예측기)
역할: '넥'에서 잘 정리된 특징 정보를 받아, 최종적인 예측 결과를 출력합니다.
작동: 이 '헤드' 부분이 이미지의 여러 스케일(크기)에서 동시에 작동합니다. "작은 물체는 여기서 찾고, 큰 물체는 저기서 찾자"라고 정해진 각자의 영역에서 최종 답안지를 작성합니다.
비유: 공장의 마지막 단계. 잘 조립된 부품(특징)을 보고, "이건 '자동차'다", "위치는 여기(Bounding Box)다", "98% 확신한다(Confidence)"라는 세 가지 정보를 담은 '제품 태그'를 찍어냅니다.
요약: 백본이 이미지를 보고 특징을 뽑아내면, 넥이 이 특징들을 다양한 크기로 조합하고, 헤드가 이 조합된 특징을 보고 최종 예측을 수행합니다.
| 버전 | 백본 (Backbone) | 넥 (Neck) | 헤드 (Head) | 핵심 특징 |
|---|---|---|---|---|
| YOLOv1 | GoogLeNet 기반 | 없음 | FC Layers | 1-Stage, Real-Time |
| YOLOv3 | Darknet-53 | FPN | 앵커 기반 (3 스케일) | 다중 스케일 탐지 |
| YOLOv4 | CSPDarknet53 | SPP + PANet | 앵커 기반 (v3와 동일) | 'Bag of Freebies/Specials' 최적화 |
| YOLOv5 | CSPDarknet | PANet | 앵커 기반 (v3/v4와 동일) | PyTorch, 모델 스케일링 (s/m/l/x) |
| YOLOv7 | E-ELAN | E-ELAN (통합됨) | RepConv 헤드 | 구조적 효율성 극대화 |
| YOLOv8 | C2f (CSP 기반) | PANet | 앵커 프리 & 분리형 | 앵커 제거, 정확도 향상 |
| YOLOv9 | GELAN | PANet (GELAN 기반) | 앵커 프리 & 분리형 | 정보 손실 최소화 |
| YOLOv10 | CSPNet (최적화) | PANet (최적화) | NMS-Free (이중 헤드) | End-to-End, NMS 제거 |
4. YOLO의 탐지 과정: '바둑판' 전략

YOLO가 이미지를 "한 번만 본다"는 것은 구체적으로 어떻게 작동하는 걸까요? 그 비밀은 바로 '바둑판' 전략에 있습니다.
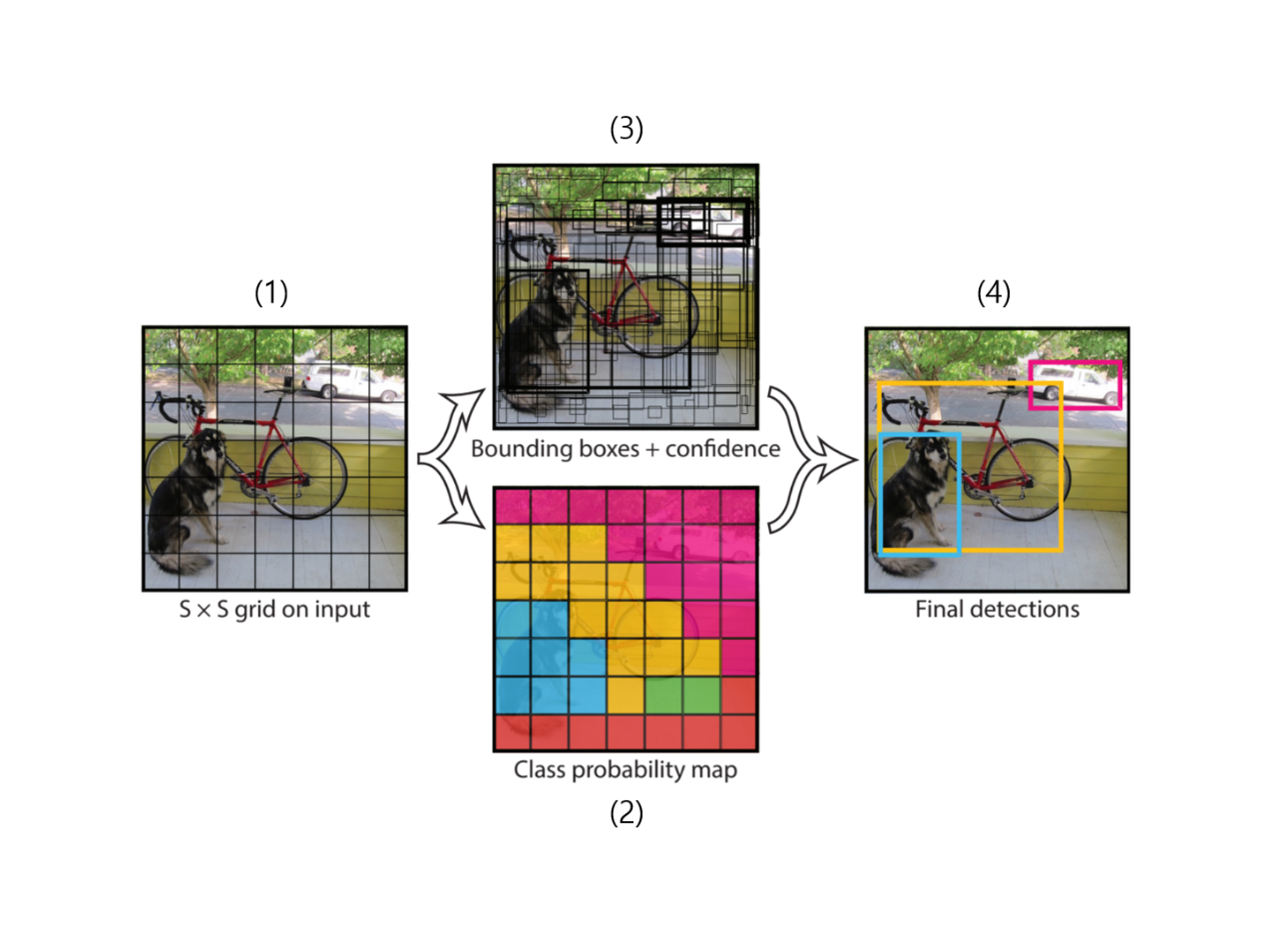
1단계: 이미지를 '바둑판'으로 나누기
YOLO는 이미지를 받으면, 일단 이미지 전체를 일정한 크기의 '바둑판(Grid)'으로 나눕니다. (예: 13x13, 19x19 등)
2단계: 각 칸에 '책임' 할당하기
이 바둑판의 각 칸(Grid Cell)은 "만약 어떤 객체의 중심점이 내 칸 안에 들어오면, 그 객체를 탐지하는 건 내 책임이다"라는 규칙을 갖습니다.
예를 들어, 고양이의 정확한 중심점이 'C-5' 칸에 있다면, 오직 'C-5' 칸만이 그 고양이를 탐지할 책임을 집니다.
3단계: 모든 칸이 '동시에' 예측하기
이제 모든 바둑판 칸들이 동시에 "내 책임 구역에 뭔가가 있을지도 몰라!"라고 외치며 예측을 쏟아냅니다. 각 칸은 여러 개의 '예측 세트'를 만들어내며, 각 세트에는 다음 3가지 정보가 포함됩니다.
경계 상자 (Bounding Box): "객체가 있다면, 여기(x, y, w, h)에 있을 거야" (위치와 크기 정보)
신뢰도 (Confidence Score): "내 상자 안에 진짜 객체가 있을 확률이 이 정도(예: 80%)야" (배경이 아니라 객체라는 확신)
클래스 확률 (Class Probability): "그게 만약 객체라면, '고양이'일 확률 95%, '강아지'일 확률 3%, '자동차'일 확률 0%..." (객체의 종류)
4단계: '정리'하기 (NMS - 비최대 억제)
3단계를 거치면, 수백 수천 개의 무분별한 예측 상자들이 만들어집니다. (예: 고양이 한 마리를 두고 10개의 칸이 전부 "고양이다!"라고 외친 상황)
이 지저분한 예측들을 정리하는 마지막 단계가 바로 '비최대 억제(NMS, Non-Maximum Suppression)'입니다.
작동:
모든 예측 상자 중 신뢰도가 가장 높은 상자(예: 98% '고양이')를 일단 선택합니다.
이 상자와 너무 많이 겹치는(즉, 같은 고양이를 가리키는) 다른 상자들(예: 80% '고양이', 75% '고양이')은 모두 '억제'시켜 지워버립니다.
남아있는 상자들 중 다시 신뢰도가 가장 높은 상자를 선택하고, 이 과정을 반복합니다.
결과: 최종적으로 각 객체당 가장 점수가 높은 '최고의 상자' 하나씩만 남게 됩니다.
5.YOLO는 실제로 어떻게 '학습'하는가?: 3가지 핵심 성적표 (Loss Function) 파헤치기
YOLO가 똑똑해지는 과정은 '시험공부'에 비유할 수 있다. 모델이 예측(답안지)을 내면, '정답지(Ground Truth)'와 비교하여 '틀린 만큼' 벌점(Loss)을 부여한다. YOLO 모델은 이 총 벌점(Total Loss)을 최소화하는 방향으로 스스로의 가중치(Weight)를 업데이트하며 학습한다.
YOLO의 시험지는 크게 3과목으로 나뉘며, 실제에서도 이 3가지 손실(Loss)을 중심으로 논의가 이루어진다.
1. Bounding Box Loss (위치 과목): "이것은 '어디에' 있는가?"
개념: '바운딩 박스(Bounding Box)'는 모델이 예측한 사물의 위치(네모 상자)를 의미한다.
손실 함수 (IoU): 이 과목의 채점 기준은 'IoU(Intersection over Union)'이다. 이는 모델이 예측한 상자와 정답 상자(Ground Truth Box)가 얼마나 정확하게 겹치는지를 0과 1 사이의 값으로 나타낸다.
비유: 두 상자가 100% 똑같이 겹치면 IoU=1 (0점 감점), 전혀 겹치지 않으면 IoU=0 (높은 감점)이다. YOLO는 학습을 통해 이 겹치는 면적을 최대화(즉, Bbox Loss를 최소화)하려 노력한다.
2. Classification Loss (종류 과목): "이것은 '무엇'인가?"
개념: 찾은 상자 안의 물체가 '사람'인지, '컵'인지, '개'인지 정확히 맞히는 과목이다.
손실 함수 (Class Loss): 이는 객관식 문제를 푸는 것과 같다. 정답은 '사람'인데 모델이 '개'라고 예측하면 높은 벌점을 받는다.
3. DFL (정밀도 과목): "얼마나 '정확하게' 맞췄는가?"
개념: Distribution Focal Loss(DFL)는 YOLO의 최신 버전에서 사용되는 고급 기술이다.
해설: 기존 모델이 '경계선은 100번 픽셀에 있다'라고 단정적으로 예측했다면, DFL은 '경계선은 100번 픽셀에 있을 확률이 90%, 99번 픽셀에 5%, 101번 픽셀에 5%'처럼 확률 분포로 예측한다.
비유: 이는 마치 흐릿한 저화질 사진을 선명한 고화질 사진으로 바꾸는 것처럼, 박스의 경계선을 훨씬 더 정밀하고 날카롭게 다듬어주는 역할을 수행한다.
YOLO의 전체 학습은 이 3가지 손실(Bbox, Class, DFL)을 동시에 최소화하려는 '줄다리기' 과정이다. 실제 R&D 환경에서는 이 손실들의 '가중치(Weight)'(W1, W2, W3)를 어떻게 조절하는지가 중요한 연구 주제가 된다. 예를 들어, '위치'보다 '종류'를 맞히는 것이 더 중요한 작업(task)일 수 있기 때문이다. (실제로 'classification loss is always big'이라는 관찰은 가중치 조절의 필요성을 뒷받침한다.)
더 나아가, 이 3가지 손실 함수는 YOLO의 '성적표'일 뿐만 아니라, 나중에 다룰 강화학습(RL) 에이전트에게 줄 '보상(Reward)의 원천'이 된다. 즉, 이 3가지 기본 개념을 이해하는 것이 AI 로보틱스 핵심 연구를 이해하는 첫걸음이다.
6. 결론: YOLO는 왜 강력할까요?
YOLO의 구조와 탐지 과정을 요약하면 이렇습니다.
구조: 이미지를 백본(특징 추출) -> 넥(특징 융합) -> 헤드(예측) 3단계를 거쳐 처리합니다.
과정: 이미지를 '바둑판'으로 나누고, 각 칸이 동시에 '상자+신뢰도+클래스'를 예측한 뒤, 'NMS'로 깔끔하게 정리합니다.
이 모든 과정이 단 하나의 거대한 신경망 파이프라인 안에서 '한 번에' 일어나기 때문에, YOLO는 다른 어떤 모델보다 빠르고 효율적인 실시간 객체 탐지가 가능한 것입니다.
'AI' 카테고리의 다른 글
| 비개발자도 1시간 만에 글로벌 결제 사이트 만드는 법 (Claude Code + PayPal MCP 완전 정복) (0) | 2026.05.23 |
|---|---|
| yolov10, rtdetr A-Z까지 알아보자 (0) | 2025.11.11 |
| DETR 모델? (feat. 초보자용 설명) (1) | 2025.11.08 |
| 원드라이브 ↔ 구글드라이브 파일 옮기기, 이렇게 하면 됩니다 (0) | 2025.10.24 |
| 생성형 AI, 일터의 생산성을 끌어올리다: 한국은 지금 어디에 와 있나? (0) | 2025.10.23 |